CHIA SẺ KIẾN THỨC
So Sánh Chi Tiết Kiến Trúc LLM Hiện Đại (2025): Từ DeepSeek V3 Đến Mistral 3 Large
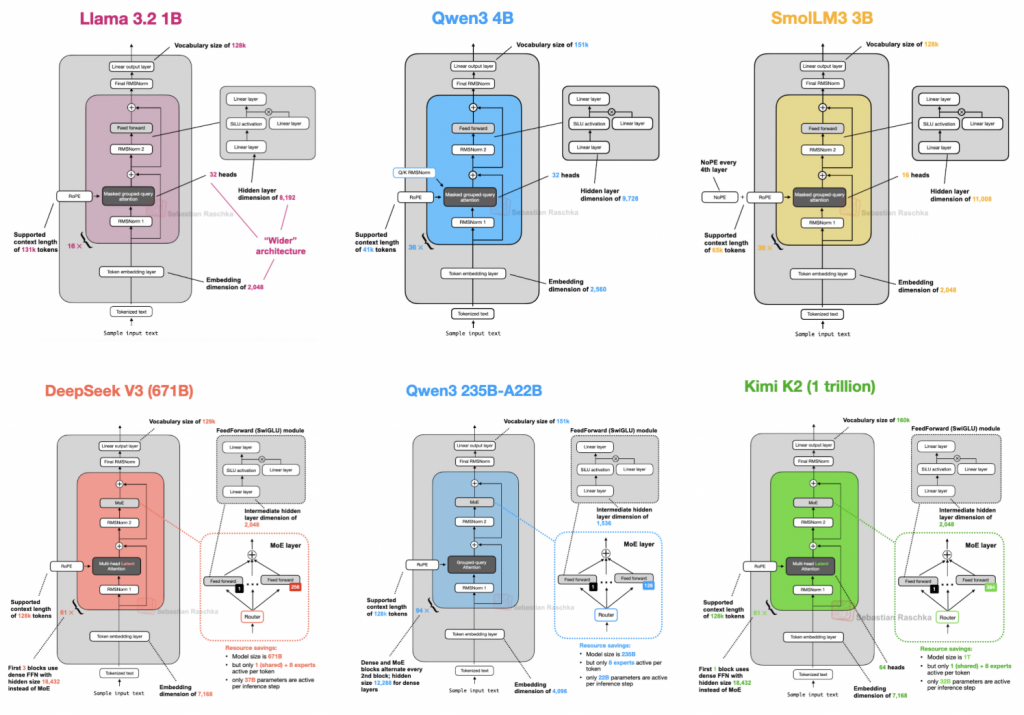
Đã 7 năm trôi qua kể từ khi kiến trúc GPT ban đầu được phát triển. Thoạt nhìn, từ GPT-2 (2019) đến DeepSeek V3 hay Llama 4 (2025), cấu trúc của chúng có vẻ vẫn rất giống nhau. Tuy nhiên, bên dưới vẻ ngoài đó là những cuộc cách mạng ngầm về kiến trúc LLM.
Bài viết này sẽ đi sâu vào phân tích các quyết định thiết kế kiến trúc của những mô hình ngôn ngữ lớn (LLM) mã nguồn mở hàng đầu hiện nay, dựa trên nghiên cứu của Tiến sĩ Sebastian Raschka.
1. DeepSeek V3/R1: Kỷ Nguyên Của Hiệu Suất Cao
DeepSeek R1 (mô hình lý luận) và V3 (nền tảng) đã tạo nên cú hích lớn nhờ hai cải tiến kiến trúc giúp tối ưu hóa tính toán vượt trội:
1.1 Multi-Head Latent Attention (MLA)
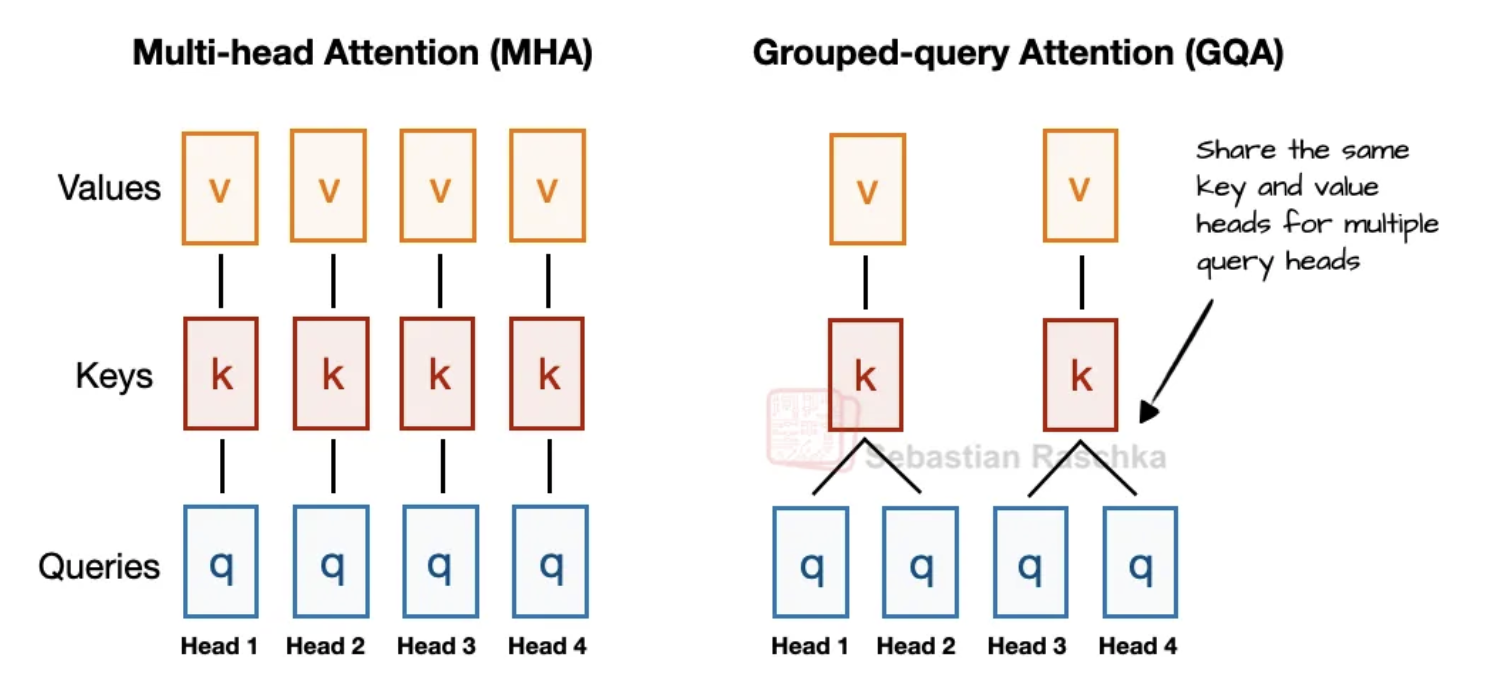
Để giảm bộ nhớ KV cache, các mô hình trước đây dùng Grouped-Query Attention (GQA). Tuy nhiên, DeepSeek chọn MLA.
-
Cơ chế: Thay vì chia sẻ đầu Key/Value như GQA, MLA nén các tensor Key và Value vào một không gian chiều thấp hơn (latent space) trước khi lưu vào cache. Khi suy luận, chúng được giải nén (project back) về kích thước ban đầu.
-
Hiệu quả: Nghiên cứu từ DeepSeek-V2 cho thấy MLA không chỉ tiết kiệm bộ nhớ ngang ngửa GQA mà còn mang lại hiệu suất mô hình tốt hơn, vượt trội so với cả Multi-Head Attention (MHA) truyền thống.
1.2 Mixture-of-Experts (MoE)
DeepSeek V3 sử dụng kiến trúc MoE với tổng cộng 671 tỷ tham số, nhưng chỉ kích hoạt 37 tỷ tham số cho mỗi token.
-
Cơ chế: Thay thế khối FeedForward dày đặc bằng nhiều chuyên gia (experts). Một bộ định tuyến (router) sẽ chọn ra các chuyên gia phù hợp nhất cho từng token.
-
Shared Expert (Chuyên gia dùng chung): Điểm độc đáo của DeepSeek là luôn kích hoạt một “chuyên gia chia sẻ” cộng với 8 chuyên gia được chọn. Chuyên gia dùng chung này giúp nắm bắt các kiến thức phổ quát, giảm tải cho các chuyên gia chuyên biệt.
2. OLMo 2: Bài Học Về Ổn Định Huấn Luyện
Mô hình từ Allen Institute for AI là hình mẫu về sự minh bạch. Về mặt kiến trúc, OLMo 2 tập trung giải quyết vấn đề ổn định khi huấn luyện quy mô lớn:
2.1 Vị Trí Chuẩn Hóa (Normalization Placement)
OLMo 2 sử dụng một biến thể của Post-Norm. Thay vì đặt RMSNorm trước khối Attention (Pre-Norm như GPT-3), họ đặt nó sau khối Attention và FeedForward, nhưng vẫn nằm trong đường dẫn dư (residual path). Điều này giúp gradient ổn định hơn.
2.2 QK-Norm
Để tránh việc các giá trị trong quá trình tính toán Attention trở nên quá lớn, OLMo 2 áp dụng RMSNorm cho cả Queries (Q) và Keys (K) trước khi tính điểm chú ý. Kỹ thuật này (QK-Norm) giúp ngăn chặn sự mất ổn định khi huấn luyện các mô hình lớn.
3. Gemma 3: Đột Phá Với Sliding Window Attention
Gemma 3 (27B) của Google chọn một hướng đi khác để tối ưu hóa bộ nhớ mà không cần dùng đến MoE.
3.1 Sliding Window Attention (Chú ý cửa sổ trượt)
-
Vấn đề: Attention toàn cục (Global Attention) tốn rất nhiều bộ nhớ vì mỗi token phải “nhìn” tất cả các token khác.
-
Giải pháp: Gemma 3 sử dụng tỷ lệ 5:1. Nghĩa là cứ 6 lớp thì có 5 lớp sử dụng Sliding Window Attention (chỉ nhìn thấy cửa sổ cục bộ 1024 token xung quanh) và chỉ 1 lớp sử dụng Global Attention.
-
Kết quả: Giảm đáng kể kích thước KV cache mà không làm giảm chất lượng mô hình (theo các nghiên cứu cắt bỏ – ablation studies).
3.2 Chuẩn Hóa Kép (Dual Normalization)
Gemma 3 đặt RMSNorm ở cả đầu vào và đầu ra của khối Attention/FeedForward. Cách tiếp cận “thừa hơn thiếu” này giúp đảm bảo sự ổn định tối đa.
3.4 (Bonus) Gemma 3n: Kiến Trúc Cho Thiết Bị Di Động
Google giới thiệu Gemma 3n, phiên bản tối ưu để chạy trên điện thoại.
-
Per-Layer Embedding (PLE): Thay vì lưu toàn bộ bảng tham số khổng lồ trong RAM, mô hình chỉ giữ các tham số cốt lõi. Các embeddings đặc thù (cho hình ảnh, âm thanh…) được stream từ bộ nhớ lưu trữ (SSD/CPU) khi cần thiết.
-
MatFormer: Mô hình được huấn luyện theo kiểu “búp bê Nga”, cho phép cắt nhỏ thành các mô hình bé hơn mà không cần huấn luyện lại.
4. Mistral Small 3.1: Tối Ưu Hóa Tốc Độ Suy Luận
Mistral Small 3.1 (24B) vượt trội Gemma 3 về tốc độ.
-
Bỏ Sliding Window: Khác với các phiên bản trước, Mistral Small 3.1 quay lại sử dụng GQA thuần túy và bỏ Sliding Window Attention.
-
Lý do: Có thể do các thư viện tối ưu hóa phần cứng (như FlashAttention) hỗ trợ GQA tốt hơn, giúp giảm độ trễ (latency) khi suy luận thực tế, dù có thể tốn VRAM hơn một chút.
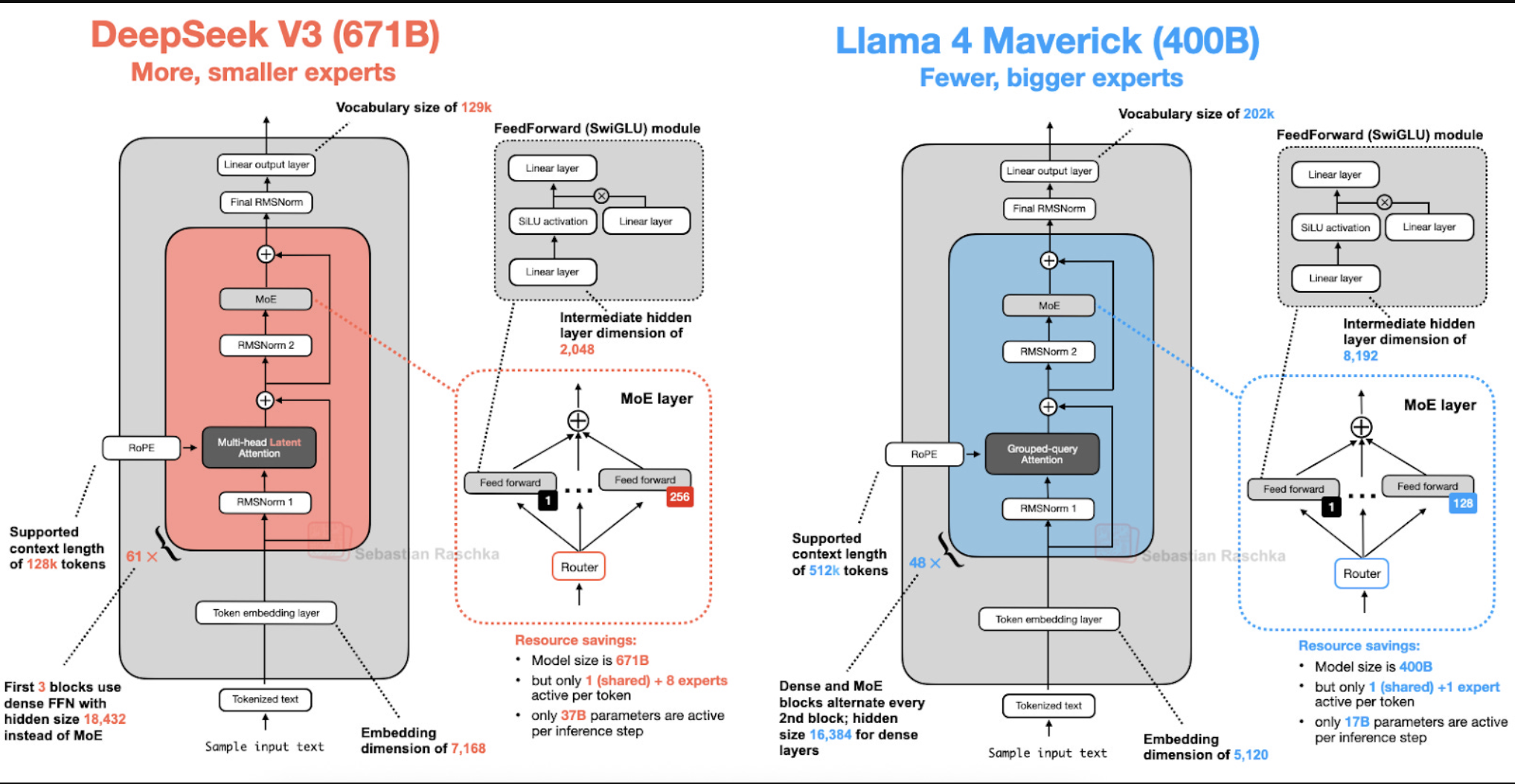
5. Llama 4: Meta Gia Nhập Cuộc Chơi MoE
Llama 4 Maverick (400B) đánh dấu bước chuyển mình của Meta sang kiến trúc MoE.
-
So sánh với DeepSeek V3:
-
DeepSeek V3: Dùng nhiều chuyên gia nhỏ (9/256 active), sử dụng MLA.
-
Llama 4: Dùng ít chuyên gia lớn (2 active), sử dụng GQA.
-
-
Cấu trúc xen kẽ: Llama 4 xen kẽ các lớp MoE và các lớp Dense (dày đặc) trong mạng lưới, thay vì dùng MoE ở tất cả các lớp. Đây là một chiến lược cân bằng giữa hiệu suất và chi phí.
6. Qwen3: Chiến Lược Phủ Kín Mọi Phân Khúc
Qwen3 tiếp tục khẳng định vị thế với dải sản phẩm rộng:
-
Qwen3 Dense (0.6B – 32B): Các mô hình nhỏ (0.6B) hoạt động cực tốt, thay thế được Llama 3 1B nhờ kiến trúc sâu hơn (nhiều lớp hơn) thay vì rộng hơn (nhiều head hơn).
-
Qwen3 MoE (A3B – A22B): Tối ưu cho suy luận quy mô lớn.
-
Bỏ Shared Expert: Khác với phiên bản Qwen2.5-MoE cũ và DeepSeek, Qwen3 loại bỏ Shared Expert. Nhóm phát triển cho biết họ không thấy lợi ích rõ rệt của Shared Expert trong khi nó lại làm phức tạp quá trình tối ưu hóa suy luận.
7. SmolLM3: Hiệu Quả Từ Sự Đơn Giản
Mô hình 3B này tập trung vào hiệu năng trên thiết bị cá nhân.
-
NoPE (No Positional Embeddings): SmolLM3 loại bỏ hoàn toàn các lớp mã hóa vị trí (như RoPE).
-
Cơ chế: Mô hình dựa hoàn toàn vào Causal Masking (mặt nạ nhân quả) để “hiểu” thứ tự từ. Các nghiên cứu cho thấy NoPE giúp mô hình tổng quát hóa tốt hơn khi gặp các văn bản dài hơn so với lúc huấn luyện (Length Generalization).
8. Kimi K2: Siêu Mô Hình 1 Nghìn Tỷ Tham Số
Kimi K2 là mô hình mã nguồn mở lớn nhất hiện nay (1T parameters).
-
Kiến trúc: Về cơ bản là phiên bản phóng to của DeepSeek V3, nhưng sử dụng nhiều chuyên gia hơn.
-
Kimi K2 Thinking: Phiên bản nâng cấp với ngữ cảnh lên tới 256k token, cạnh tranh trực tiếp với các mô hình lý luận hàng đầu.
-
Tối ưu hóa: Sử dụng bộ tối ưu hóa Muon thay vì AdamW, giúp đường cong loss khi huấn luyện mượt mà và hội tụ tốt hơn đáng kinh ngạc.
9. GPT-OSS: OpenAI Trở Lại Mã Nguồn Mở
GPT-OSS (120B và 20B) là động thái bất ngờ từ OpenAI.
-
Rộng hơn Sâu: GPT-OSS có kiến trúc “béo” (wide) thay vì “cao” (deep). Số chiều embedding lớn (2880 so với 2048 của Qwen3) giúp tính toán song song tốt hơn.
-
Bias & Attention Sinks: OpenAI giữ lại các hệ số Bias (vốn bị bỏ ở Llama) và sử dụng Attention Sinks (các token mồi luôn được chú ý) để ổn định mô hình khi xử lý văn bản dài.
10. Grok 2.5: Cái Nhìn Vào Hệ Thống Sản Xuất
Mô hình 270B của xAI mang đến cái nhìn hiếm hoi vào một hệ thống đang chạy thực tế (production).
-
MoE Cổ Điển: Sử dụng ít chuyên gia nhưng kích thước rất lớn (8 chuyên gia).
-
Shared Expert “Trá hình”: Sử dụng một khối SwiGLU lớn độc lập chạy song song, đóng vai trò như một chuyên gia dùng chung khổng lồ để xử lý kiến thức nền.
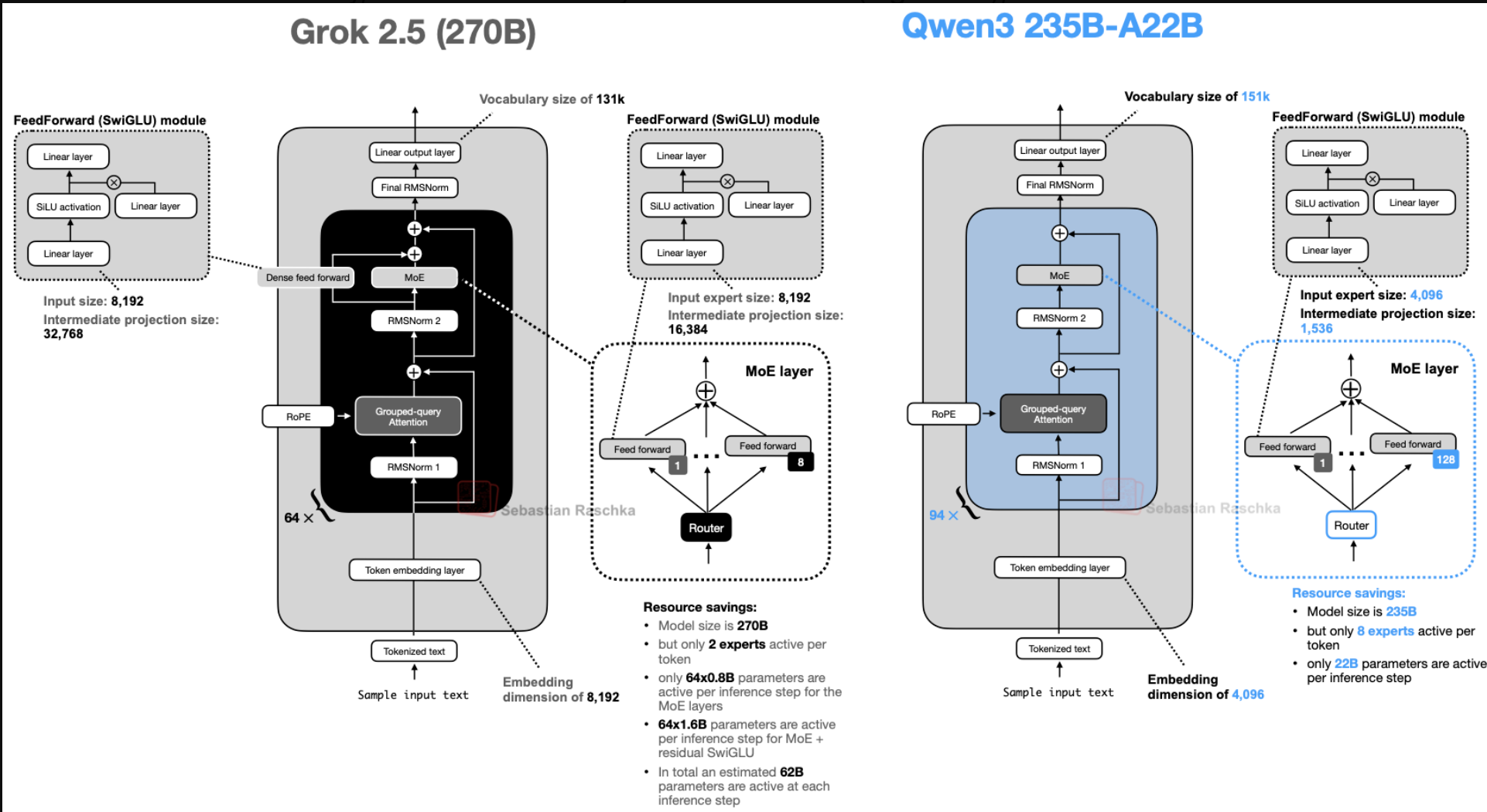
11. GLM-4.5: Lai Tạo Cho Tác Vụ Agent
Mô hình 355B này được tối ưu cho việc gọi hàm (function calling) và làm Agent.
-
Khởi đầu Dense: 3 lớp đầu tiên của GLM-4.5 là các lớp Dense hoàn toàn, trước khi chuyển sang MoE.
-
Lý do: Giúp mô hình hình thành các biểu diễn ngữ nghĩa ổn định ở các tầng thấp trước khi bị phân tán bởi cơ chế định tuyến (routing) của MoE.
12. Qwen3-Next: Đột Phá Về Cơ Chế Attention
Phiên bản nâng cấp của Qwen3 giới thiệu cơ chế lai (Hybrid Attention) đầy táo bạo:
-
Gated DeltaNet: Một dạng Linear Attention cực nhanh, thay thế cho Attention truyền thống.
-
Tỷ lệ 3:1: Cứ 3 lớp dùng Gated DeltaNet (xử lý nhanh) thì có 1 lớp dùng Gated Attention (xử lý chính xác).
-
Multi-Token Prediction: Dự đoán cùng lúc 4 token tiếp theo (thay vì 1). Điều này giúp tăng tốc độ huấn luyện và hỗ trợ suy luận suy đoán (speculative decoding) hiệu quả hơn.
13. MiniMax-M2: Sự Trở Lại Của Full Attention
Dù phiên bản M1 thử nghiệm với Linear Attention, MiniMax-M2 (230B) quay lại dùng Full Attention để đảm bảo chất lượng lý luận cao nhất.
-
Per-Layer QK-Norm: Áp dụng chuẩn hóa RMSNorm riêng biệt cho từng đầu chú ý (attention head). Đây là mức độ kiểm soát cực kỳ chi tiết, giúp cân bằng đóng góp của từng head.
-
Partial RoPE: Chỉ áp dụng mã hóa vị trí xoay (RoPE) cho một nửa số chiều của vector. Nửa còn lại giữ nguyên để bảo toàn thông tin nội dung, giúp xử lý văn bản dài tốt hơn.
14. Kimi Linear: Tối Ưu Hóa Bộ Nhớ Cho Ngữ Cảnh Dài
Kimi Linear (48B) là một nỗ lực khác trong việc giảm chi phí bộ nhớ.
-
Kiến trúc Lai: Kết hợp Gated DeltaNet (bộ nhớ thấp) và MLA (chất lượng cao).
-
Kimi Delta Attention: Cải tiến Gated DeltaNet bằng cách thêm cơ chế kiểm soát bộ nhớ theo từng kênh (channel-wise gating), giúp mô hình “nhớ” được thông tin quan trọng lâu hơn trong các tác vụ lý luận dài.
15. Olmo 3 Thinking: Sự Tiến Hóa Của Mô Hình Mở
Olmo 3 tiếp tục truyền thống minh bạch tuyệt đối của Allen AI.
-
7B Model: Sử dụng Sliding Window Attention để tối ưu hóa cho các GPU bộ nhớ thấp.
-
32B Model: Sử dụng Grouped-Query Attention (GQA) để cân bằng giữa tốc độ và chất lượng.
-
YaRN: Sử dụng kỹ thuật YaRN (một cách điều chỉnh RoPE) để mở rộng độ dài ngữ cảnh lên 64k token mà không cần huấn luyện lại quá nhiều.
16. DeepSeek V3.2: Sparse Attention (Chú Ý Thưa Thớt)
Ra mắt ngay sau V3, phiên bản V3.2 giới thiệu cơ chế Sparse Attention.
-
Cơ chế: Thay vì tính toán sự chú ý cho tất cả các từ, mô hình học cách bỏ qua các từ không quan trọng.
-
Hiệu quả: Giúp tăng tốc độ tính toán đáng kể mà vẫn giữ được chất lượng tương đương các mô hình hàng đầu như GPT-5.1 (giả định trong bài viết).
17. Mistral 3: Bản Sao Hoàn Hảo?
Mistral 3 Large (675B) gây bất ngờ khi có kiến trúc gần như y hệt DeepSeek V3.
-
Sự khác biệt: Mistral tăng kích thước của mỗi chuyên gia lên gấp đôi và giảm số lượng chuyên gia đi một nửa.
-
Ý nghĩa: Điều này cho thấy kiến trúc MoE + MLA của DeepSeek đang trở thành “chuẩn mực vàng” mới (Gold Standard) cho cộng đồng AI mã nguồn mở, được các ông lớn khác học tập và tinh chỉnh.
Tổng Kết
Bức tranh kiến trúc LLM năm 2025 cho thấy sự hội tụ về ý tưởng nhưng đa dạng về cách thực thi:
-
MoE là vua: Để mở rộng quy mô lên hàng trăm tỷ tham số mà vẫn chạy nhanh.
-
Tối ưu hóa Attention: MLA, Linear Attention và Sliding Window đang dần thay thế MHA truyền thống.
-
Ổn định là trên hết: QK-Norm, RMSNorm và các kỹ thuật chuẩn hóa đóng vai trò then chốt để huấn luyện các siêu mô hình.
Việc hiểu rõ 17 mô hình này giúp chúng ta thấy được sự tiến hóa tinh vi của trí tuệ nhân tạo, từ những khối gạch thô sơ ban đầu thành những tòa nhà chọc trời phức tạp và hiệu quả.
>>>> Xem thêm: Mastering RAG: Cẩm Nang Toàn Diện Xây Dựng Ứng Dụng AI Thế Hệ Mới

