CHIA SẺ KIẾN THỨC
Context Engineering: Hướng dẫn tối ưu ngữ cảnh cho AI
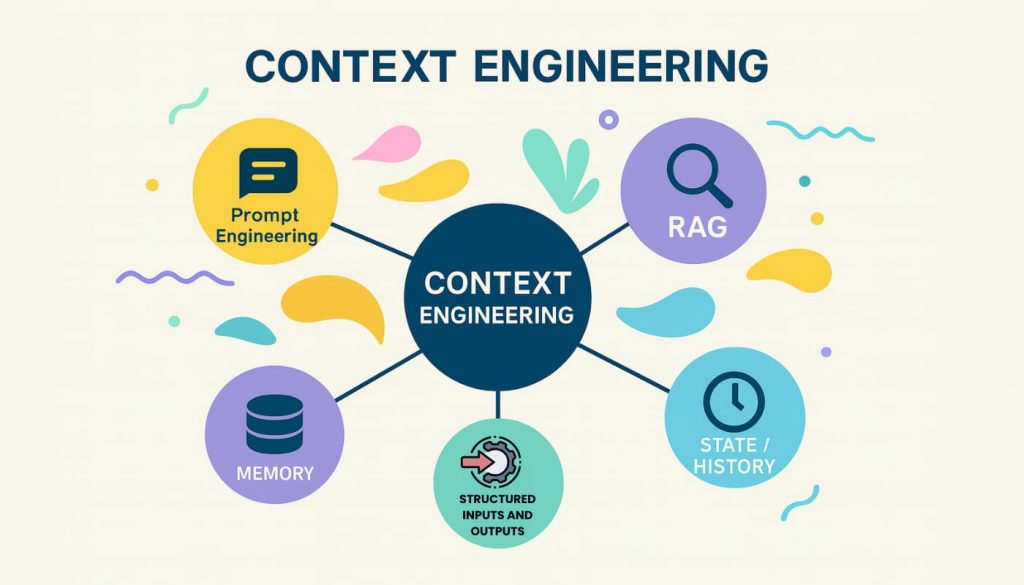
Khám phá Context Engineering là gì qua hướng dẫn đầy đủ và ví dụ thực tế. Tìm hiểu cách tối ưu hóa ngữ cảnh cho LLM, từ system prompt đến AI agent workflow chi tiết.
Vài năm trước, nhiều nhà nghiên cứu AI hàng đầu đã cho rằng prompt engineering sẽ sớm lỗi thời. Rõ ràng, họ đã hoàn toàn sai lầm. Trên thực tế, prompt engineering giờ đây còn quan trọng hơn bao giờ hết. Tầm quan trọng của nó rất lớn. Vì vậy, nó đang được tái định vị dưới một cái tên mới, bao quát hơn: Context Engineering (Kỹ thuật Ngữ cảnh).
Đây không chỉ là một thuật ngữ hoa mỹ. Nó mô tả chính xác quá trình tinh chỉnh các chỉ dẫn và ngữ cảnh. Đây là những thông tin mà một Mô hình Ngôn ngữ Lớn (LLM) cần để thực hiện nhiệm vụ hiệu quả. Bài viết này là một hướng dẫn context engineering chi tiết. Chúng tôi sẽ đi từng bước, đưa kỹ thuật ngữ cảnh vào hành động trong việc phát triển một AI agent workflow.
1. Context Engineering là gì? Sự tiến hóa của Prompt Engineering
Nhiều người nghi ngờ prompt engineering như một kỹ năng nghiêm túc. Nguyên nhân là do họ nhầm lẫn nó với “blind prompting”. “Blind prompting” chỉ đơn giản là nhập một mô tả ngắn vào LLM. Đó chỉ đơn thuần là đặt câu hỏi. Ngược lại, prompt engineering đòi hỏi sự suy tính cẩn thận hơn. Nó cần chú trọng vào ngữ cảnh và cấu trúc của câu lệnh.
Context Engineering là giai đoạn tiếp theo. Ở đây, bạn không chỉ viết một câu lệnh đơn thuần. Bạn còn phải kiến trúc toàn bộ ngữ cảnh. Quá trình này thường đòi hỏi các phương pháp chặt chẽ. Mục đích là để thu thập, nâng cao và tối ưu hóa ngữ cảnh cho LLM.
Từ góc độ nhà phát triển, kỹ thuật ngữ cảnh là một quy trình lặp đi lặp lại. Mục tiêu là tối ưu hóa chỉ dẫn và ngữ cảnh bạn cung cấp cho LLM. Quá trình này cũng bao gồm các quy trình chính thức, như pipeline đánh giá, để đo lường hiệu quả.
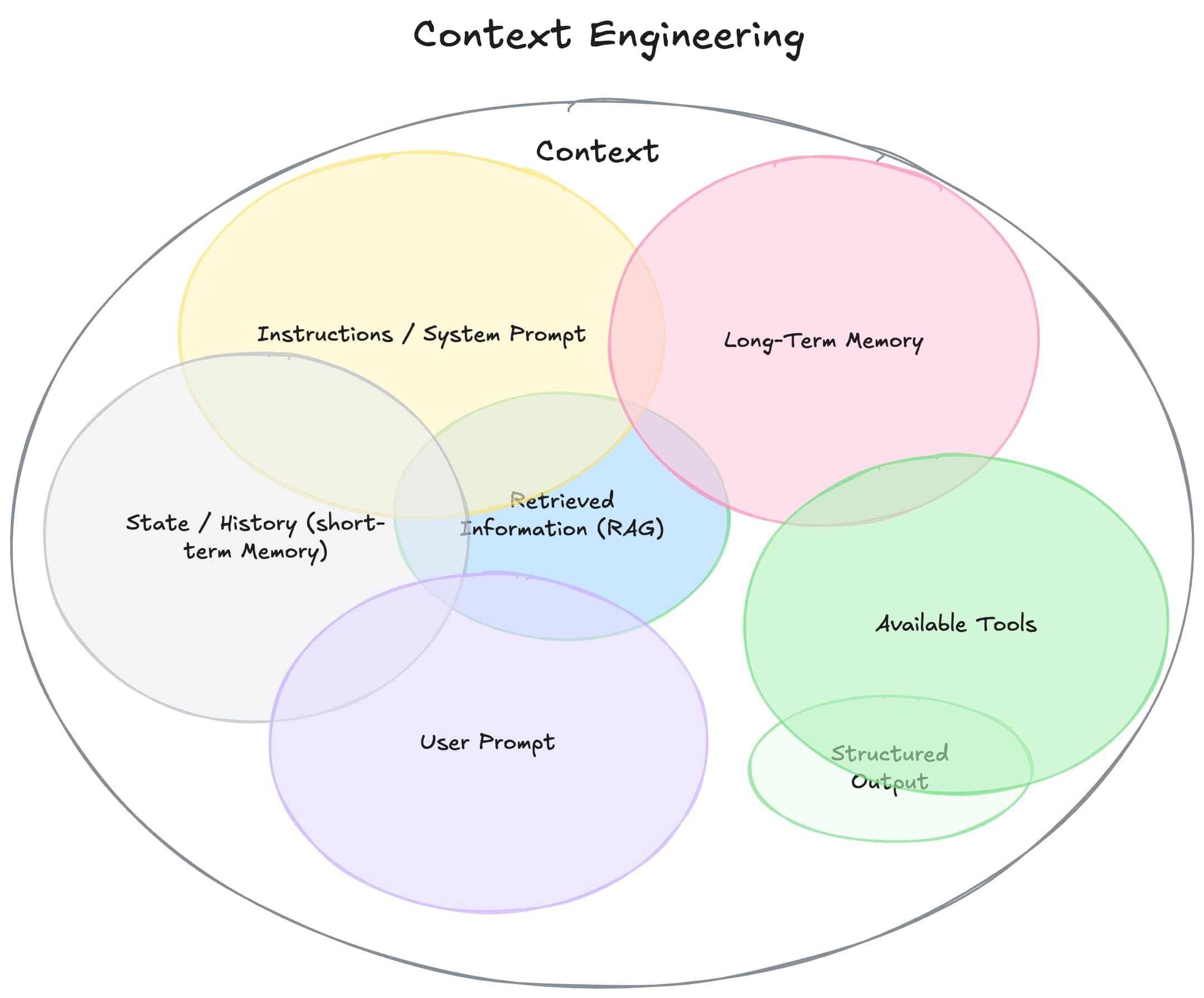
Định nghĩa rộng hơn cho Context Engineering là gì: Quá trình thiết kế và tối ưu hóa chỉ dẫn cùng ngữ cảnh liên quan. Mục tiêu là để LLM và các mô hình AI tiên tiến thực hiện nhiệm vụ một cách hiệu quả. Điều này bao gồm:
-
Thiết kế và quản lý chuỗi prompt (prompt chains).
-
Tinh chỉnh instructions/system prompts.
-
Quản lý các yếu tố động (dữ liệu người dùng, ngày/giờ).
-
Tìm kiếm và chuẩn bị kiến thức (RAG).
-
Tăng cường truy vấn (Query augmentation).
-
Định nghĩa và hướng dẫn công cụ cho hệ thống agent.
-
Chuẩn bị ví dụ (few-shot demonstrations).
-
Cấu trúc hóa đầu vào và đầu ra (dấu phân cách, JSON schema).
-
Bộ nhớ ngắn hạn (trạng thái) và dài hạn (truy xuất từ vector store).
Nói cách khác, bạn đang cố gắng tối ưu hóa thông tin trong cửa sổ ngữ cảnh của LLM. Đồng thời bạn phải lọc bỏ thông tin nhiễu. Đây là một khoa học riêng, đòi hỏi đo lường hiệu suất LLM một cách có hệ thống.
2. Ví dụ Thực tế
Hãy xem một ví dụ cụ thể về công việc kỹ thuật ngữ cảnh. Đó là một ứng dụng nghiên cứu sâu đa tác tử (multi-agent). Quy trình làm việc của agent được xây dựng bên trong n8n, nhưng công cụ không quan trọng.
Trong quy trình này, Search Planner Agent chịu trách nhiệm tạo kế hoạch tìm kiếm. Kế hoạch này dựa trên truy vấn của người dùng.
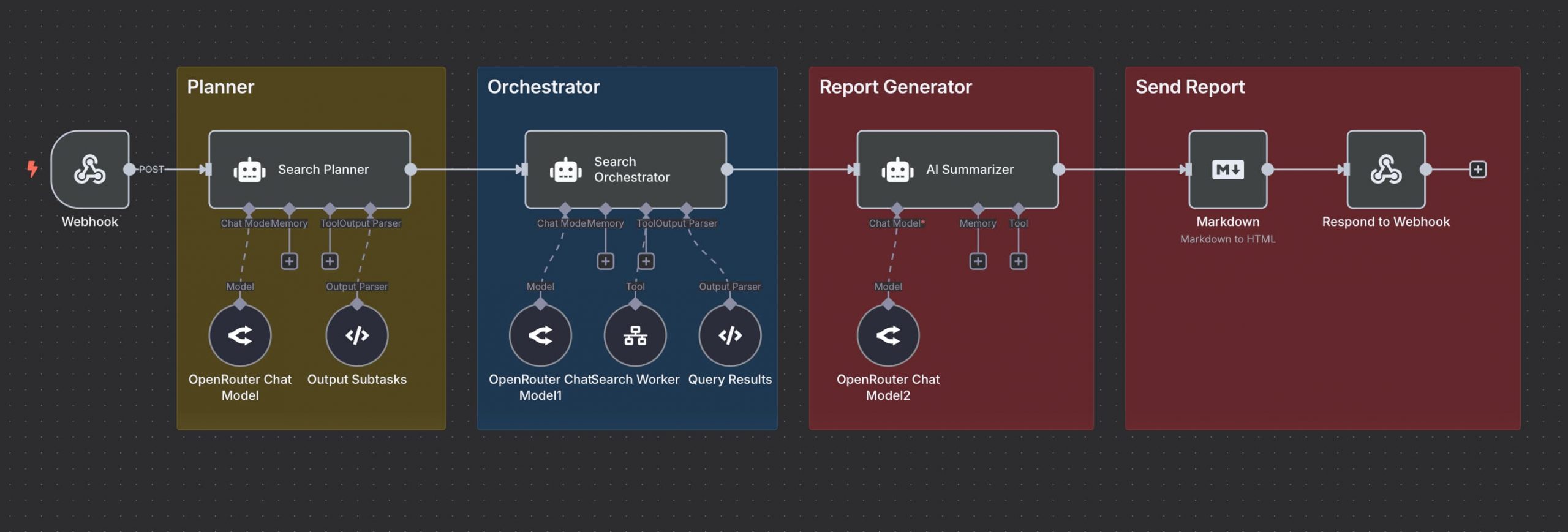
2.1. System Prompt (Lời nhắc hệ thống)
Dưới đây là system prompt được tạo cho agent phụ này.
Bạn là một chuyên gia lập kế hoạch nghiên cứu. Nhiệm vụ của bạn là chia nhỏ một truy vấn nghiên cứu phức tạp (được giới hạn bởi <user_query></user_query>) thành các nhiệm vụ con tìm kiếm cụ thể, mỗi nhiệm vụ tập trung vào một khía cạnh hoặc loại nguồn khác nhau. Ngày giờ hiện tại là: {{ $now.toISO() }} Với mỗi nhiệm vụ con, hãy cung cấp: 1. Một ID chuỗi duy nhất cho nhiệm vụ con (ví dụ: 'subtask_1', 'news_update') 2. Một truy vấn tìm kiếm cụ thể tập trung vào một khía cạnh của truy vấn chính 3. Loại nguồn để tìm kiếm (web, news, academic, specialized - web, tin tức, học thuật, chuyên ngành) 4. Mức độ liên quan về thời gian (today, last week, recent, past_year, all_time - hôm nay, tuần trước, gần đây, năm qua, mọi lúc) 5. Lĩnh vực tập trung nếu có (technology, science, health, etc. - công nghệ, khoa học, sức khỏe, v.v.) 6. Mức độ ưu tiên (1-cao nhất đến 5-thấp nhất) Tất cả các trường (id, query, source_type, time_period, domain_focus, priority) là bắt buộc cho mỗi nhiệm vụ con, ngoại trừ time_period và domain_focus có thể là null nếu không áp dụng. Tạo 2 nhiệm vụ con để cùng nhau cung cấp phạm vi bao quát toàn diện về chủ đề. Tập trung vào các khía cạnh, quan điểm hoặc nguồn thông tin khác nhau.
Mỗi nhiệm vụ con sẽ bao gồm các thông tin sau: id: str query: str source_type: str # ví dụ: "web", "news", "academic", "specialized" time_period: Optional[str] = None # ví dụ: "today", "last week", "recent", "past_year", "all_time" domain_focus: Optional[str] = None # ví dụ: "technology", "science", "health" priority: int # 1 (cao nhất) đến 5 (thấp nhất) Sau khi có được thông tin các nhiệm vụ con ở trên, bạn sẽ thêm hai trường bổ sung. Đó là start_date và end_date. Suy luận thông tin này dựa trên ngày hiện tại và time_period đã chọn. start_date và end_date phải sử dụng định dạng như trong ví dụ dưới đây: "start_date": "2024-06-03T06:00:00.000Z", "end_date": "2024-06-11T05:59:59.999Z",
Prompt này đòi hỏi sự cân nhắc kỹ lưỡng về ngữ cảnh chính xác mà chúng ta cung cấp.
2.2. Hướng dẫn chi tiết
Instructions là những chỉ thị cấp cao được cung cấp cho hệ thống.
Bạn là một chuyên gia lập kế hoạch nghiên cứu. Nhiệm vụ của bạn là chia nhỏ một truy vấn nghiên cứu phức tạp (được giới hạn bởi <user_query></user_query>) thành các nhiệm vụ con tìm kiếm cụ thể, mỗi nhiệm vụ tập trung vào một khía cạnh hoặc loại nguồn khác nhau.
Nhiều người mới bắt đầu và cả lập trình viên có kinh nghiệm cũng sẽ dừng lại ở đây. Nhưng với prompt đầy đủ ở trên, bạn có thể thấy chúng ta cần nhiều ngữ cảnh hơn. Đó chính là Context Engineering.
2.3. Đầu vào từ người dùng
Đầu vào của người dùng không được hiển thị trong system prompt, nhưng đây là một ví dụ:
<user_query> What's the latest dev news from OpenAI? </user_query>Việc sử dụng các dấu phân cách (delimiters) giúp cấu trúc prompt tốt hơn. Nó cũng tránh nhầm lẫn và làm rõ đâu là đầu vào của người dùng.
2.4. Đầu vào & Đầu ra có cấu trúc
Tác giả đã dành nhiều công sức cho các chi tiết về nhiệm vụ con.
Với mỗi nhiệm vụ con, hãy cung cấp: 1. Một ID chuỗi duy nhất cho nhiệm vụ con (ví dụ: 'subtask_1', 'news_update') 2. Một truy vấn tìm kiếm cụ thể tập trung vào một khía cạnh của truy vấn chính 3. Loại nguồn để tìm kiếm (web, news, academic, specialized) 4. Mức độ liên quan về thời gian (today, last week, recent, past_year, all_time) 5. Lĩnh vực tập trung nếu có (technology, science, health, etc.) 6. Mức độ ưu tiên (1-cao nhất đến 5-thấp nhất) Tất cả các trường (id, query, source_type, time_period, domain_focus, priority) là bắt buộc cho mỗi nhiệm vụ con, ngoại trừ time_period và domain_focus có thể là null nếu không áp dụng. Tạo 2 nhiệm vụ con để cùng nhau cung cấp phạm vi bao quát toàn diện về chủ đề. Tập trung vào các khía cạnh, quan điểm hoặc nguồn thông tin khác nhau. Ở đây, chúng ta cấu trúc một danh sách thông tin cần thiết. Kèm theo đó là gợi ý/ví dụ để định hướng quá trình tạo dữ liệu. Nếu bạn không yêu cầu mức độ ưu tiên theo thang điểm 1-5, hệ thống có thể sử dụng thang 1-10. Ngữ cảnh này rất quan trọng!
Sức mạnh của Structured Output cho LLM
Để có được đầu ra nhất quán, chúng ta cũng cung cấp ngữ cảnh về định dạng. Dưới đây là ví dụ về định dạng và kiểu trường mong đợi.
Mỗi nhiệm vụ con sẽ bao gồm các thông tin sau:
id: str
query: str
source_type: str # ví dụ: "web", "news", "academic", "specialized"
time_period: Optional[str] = None # ví dụ: "today", "last week", "recent", "past_year", "all_time"
domain_focus: Optional[str] = None # ví dụ: "technology", "science", "health"
priority: int # 1 (cao nhất) đến 5 (thấp nhất)
Ngoài ra, các công cụ như n8n cho phép cung cấp một ví dụ JSON:
{
"subtasks": [
{
"id": "openai_latest_news",
"query": "latest OpenAI announcements and news",
"source_type": "news",
"time_period": "recent",
"domain_focus": "technology",
"priority": 1,
"start_date": "2025-06-03T06:00:00.000Z",
"end_date": "2025-06-11T05:59:59.999Z"
},
{
"id": "openai_official_blog",
"query": "OpenAI official blog recent posts",
"source_type": "web",
"time_period": "recent",
"domain_focus": "technology",
"priority": 2,
"start_date": "2025-06-03T06:00:00.000Z",
"end_date": "2025-06-11T05:59:59.999Z"
},
...
}
Sau đó, công cụ sẽ tự động tạo ra cấu trúc (schema) từ những ví dụ này. Điều này cho phép hệ thống phân tích và tạo ra các kết quả đầu ra có cấu trúc chuẩn xác, như trong ví dụ dưới đây:
[ { "action": "parse", "response": { "output": { "subtasks": [ { "id": "subtask_1", "query": "Các thông báo HOẶC tin tức HOẶC cập nhật gần đây của OpenAI", "source_type": "news", "time_period": "gần đây", "domain_focus": "công nghệ", "priority": 1, "start_date": "2025-06-24T16:35:26.901Z", "end_date": "2025-07-01T16:35:26.901Z" }, { "id": "subtask_2", "query": "Blog chính thức của OpenAI HOẶC thông cáo báo chí", "source_type": "web", "time_period": "gần đây", "domain_focus": "công nghệ", "priority": 1.2, "start_date": "2025-06-24T16:35:26.901Z", "end_date": "2025-07-01T16:35:26.901Z" } ] } } } ]
2.5. Công cụ
Dùng n8n để xây dựng agent, việc đưa ngày giờ hiện tại vào ngữ cảnh rất dễ dàng. Bạn có thể làm như sau:
The current date and time is: {{ $now.toISO() }}
Đây là một hàm đơn giản, tiện dụng được gọi trong n8n, nhưng thông thường người ta sẽ xây dựng nó như một công cụ chuyên dụng để giúp mọi thứ linh hoạt hơn (ví dụ: chỉ lấy ngày giờ nếu câu hỏi yêu cầu). Đó chính là ý nghĩa của Kỹ thuật Ngữ cảnh. Nó buộc bạn, người xây dựng hệ thống, phải đưa ra quyết định cụ thể về việc nên cung cấp ngữ cảnh nào và khi nào nên cung cấp cho Mô hình Ngôn ngữ Lớn (LLM). Điều này rất tuyệt vì nó giúp loại bỏ các giả định và sự thiếu chính xác khỏi ứng dụng của bạn.
Ngày và giờ là ngữ cảnh quan trọng cho hệ thống; nếu không, nó có xu hướng hoạt động không tốt với các câu hỏi đòi hỏi kiến thức về ngày giờ hiện tại. Ví dụ, nếu tôi yêu cầu hệ thống tìm tin tức công nghệ mới nhất từ OpenAI trong tuần trước, nó sẽ chỉ đoán mò ngày giờ, dẫn đến các truy vấn không tối ưu và kết quả là các tìm kiếm trên web sẽ không chính xác. Khi hệ thống có ngày và giờ chính xác, nó có thể suy luận ra khoảng thời gian tốt hơn, điều này rất quan trọng đối với “agent” tìm kiếm và các công cụ khác. Tôi đã thêm điều này vào như một phần của ngữ cảnh (bằng cách ra lệnh cho LLM) để nó tự tạo ra khoảng thời gian:
Sau khi có được thông tin về các tác vụ con ở trên, bạn sẽ thêm hai trường thông tin nữa. Chúng tương ứng với start_date (ngày bắt đầu) và end_date (ngày kết thúc). Hãy suy luận thông tin này dựa vào ngày hiện tại và time_period (khoảng thời gian) đã chọn. start_date và end_date nên sử dụng định dạng như trong ví dụ dưới đây: "start_date": "2024-06-03T06:00:00.000Z",
"end_date": "2024-06-11T05:59:59.999Z",
Chúng ta đang tập trung vào “agent lập kế hoạch” (planning agent) trong kiến trúc của mình, vì vậy không có quá nhiều công cụ cần thêm vào đây. Công cụ duy nhất hợp lý để thêm vào là một “công cụ truy xuất” (retrieval tool) có chức năng lấy ra các tác vụ con liên quan dựa trên một câu hỏi.
2.6. Truy xuất Tăng cường và Bộ nhớ (RAG & Memory)
Phiên bản đầu của ứng dụng này không cần bộ nhớ ngắn hạn. Tuy nhiên, chúng ta có thể xây dựng một phiên bản lưu vào bộ nhớ đệm (cache) các truy vấn con.
Nếu một truy vấn tương tự đã được dùng trước đây, hệ thống có thể lưu trữ kết quả. Chúng sẽ được lưu vào một kho vector và được tìm kiếm lại. Điều này giúp tránh việc phải tạo một bộ truy vấn con mới. Hãy nhớ, mỗi lần gọi API của LLM đều làm tăng độ trễ và chi phí.
2.7. Trạng thái và Ngữ cảnh Lịch sử
Một phần quan trọng của dự án là tối ưu hóa kết quả cuối cùng. Trong nhiều trường hợp, hệ thống agent có thể cần xem xét lại các truy vấn và dữ liệu. Điều này có nghĩa là hệ thống cần truy cập vào các trạng thái trước đó. Nó cũng cần toàn bộ ngữ cảnh lịch sử của hệ thống. Ngữ cảnh này sẽ phụ thuộc vào mục tiêu tối ưu hóa của bạn.
3. Kỹ thuật Ngữ cảnh Nâng cao
Có nhiều khía cạnh khác của Context Engineering mà chúng ta chưa đề cập, chẳng hạn như:
-
Nén ngữ cảnh (Context compression)
-
Kỹ thuật quản lý ngữ cảnh (Context management)
-
An toàn ngữ cảnh (Context safety)
-
Đánh giá hiệu quả ngữ cảnh (Evaluating context effectiveness)
Ngữ cảnh có thể bị loãng hoặc trở nên không hiệu quả. Điều này đòi hỏi các quy trình đánh giá đặc biệt để nắm bắt những vấn đề này.
4. Tài nguyên tham khảo hữu ích
Để tìm hiểu sâu hơn, bạn có thể tham khảo các bài viết và tài liệu từ những chuyên gia, tổ chức hàng đầu trong lĩnh vực này:
-
Prompting Guide: https://www.promptingguide.ai/
-
Lance Martin on Context Engineering: https://rlancemartin.github.io/2025/06/23/context_engineering/
-
Andrej Karpathy on X: https://x.com/karpathy/status/1737902205765607626
-
Phil Schmid on Context Engineering: https://www.philschmid.de/context-engineering
-
The Skill That’s Replacing Prompt Engineering: https://simple.ai/p/the-skill-thats-replacing-prompt-engineering?
-
12 Factor Agents by Humanloop: https://github.com/humanloop/12-factor-agents
-
The Rise of Context Engineering by LangChain: https://blog.langchain.com/the-rise-of-context-engineering/
5. Câu hỏi thường gặp (FAQ)
1. Sự khác biệt thực sự giữa Prompt Engineering và Context Engineering là gì?
Prompt Engineering thường tập trung vào việc tạo ra một câu lệnh tối ưu. Context Engineering có phạm vi rộng hơn. Nó bao gồm việc thiết kế và quản lý TOÀN BỘ ngữ cảnh: prompt, dữ liệu, công cụ, bộ nhớ, cấu trúc đầu ra, và quy trình đánh giá.
2. Tại sao đầu ra có cấu trúc (structured output) lại được nhấn mạnh nhiều như vậy?
Trong các hệ thống phức tạp như AI agent workflow, đầu ra của một agent này là đầu vào của agent khác. Đầu ra có cấu trúc (ví dụ: JSON) đảm bảo dữ liệu được truyền đi một cách nhất quán, không lỗi. Điều này giúp toàn bộ hệ thống hoạt động ổn định.
3. Tôi có cần phải là một chuyên gia lập trình để áp dụng Context Engineering không?
Các khái niệm cơ bản thì không đòi hỏi kỹ năng lập trình cao. Ví dụ như cung cấp hướng dẫn rõ ràng hay ví dụ cụ thể. Tuy nhiên, để triển khai các phần nâng cao như Tool Calling, RAG, hay quản lý bộ nhớ, kiến thức về lập trình và API là cần thiết.
6. Kết luận
Context Engineering không chỉ là một thuật ngữ thời thượng. Nó là sự công nhận và hệ thống hóa một quy trình sâu sắc hơn. Nó là nghệ thuật và khoa học trong việc kiến trúc toàn bộ hệ sinh thái thông tin. Hệ sinh thái này vận hành xung quanh một mô hình AI.
Việc nắm vững Context Engineering là gì qua hướng dẫn đầy đủ này sẽ giúp bạn chuyển mình. Bạn sẽ đi từ vai trò “người viết prompt” thành “kiến trúc sư ngữ cảnh”. Hãy bắt đầu áp dụng tư duy này vào dự án tiếp theo. Đừng chỉ dừng lại ở một câu lệnh. Hãy suy nghĩ về toàn bộ ngữ cảnh. Đó chính là chìa khóa để xây dựng các ứng dụng AI đột phá và đáng tin cậy.
Bắt đầu đào tạo AI cho đội ngũ ngay hôm nay!
CES Global thiết kế chương trình đào tạo AI theo nhu cầu doanh nghiệp – dễ tiếp cận, dễ ứng dụng và có thể triển khai nội bộ ngay.

